Ensemble Systems & Learn++
Robi Polikar
For a complete list of our works please see List of Publications
Ensemble Systems
In matters of great importance that has financial, medical, social, or other implications, we often seek a second opinion before making a decision, sometimes a third, and sometimes many more. In doing so, we somehow weigh the individual opinions, and combine them through some thought process to reach a final decision that is presumably the most informed one. The process of consulting “several experts” before making a final decision – what may be second nature to us – has recently been rediscovered by computational intelligence community for automated decision making applications, and it has emerged as a popular and heavily researched area. Also known under various other names, such as multiple classifier systems, committee of classifiers, or mixture of experts, ensemble systems have shown to produce favorable results compared to those of single expert systems for a broad range of applications and under a variety of scenarios.
Now Available: For a review of ensemble systems, please see the new review / tutorial papers below.
- Polikar R., “Ensemble Based Systems in Decision Making,” IEEE Circuits and Systems Magazine, vol.6, no. 3, pp. 21-45, 2006
- Polikar R., “Bootstrap Inspired Techniques in Computational Intelligence,” IEEE Signal Processing Magazine, vol.24, no. 4, pp. 56-72, 2007
- Polikar R., “Ensemble Learning,” Scholarpedia, 2008.
- Ditzler, Roveri, Alippi and Polikar, “Learning in Nonstationary Environments, a Survey,” IEEE Computational Intelligence Magazine, vol. 10, no. 4, pp. 12-25, 2015. IEEE CIS Magazine Best paper Award



At SPPRL we are looking at various applications and novel uses of ensemble systems, such as:
Ensemble Systems
Much of the recent history of machine learning research has focused on learning from data assumed to be drawn from a fixed, yet unknown distribution. Learning in a nonstationary environment (also known as concept drift), where the underlying data distribution changes over time, however, has received much less attention despite the omnipresence of applications that generate inherently nonstationary data. While algorithms that attempt to learn in such environments have recently started to appear in the literature, these algorithms are mostly ad hoc and heuristic in nature with many free parameters to be fine-tuned, make restrictive assumptions that do not generally hold in real world (slow / gradual drift, non-cyclical environments, no new classes, or availability of old data at all times, etc.), and have not been tested on large scale real world test beds. Yet, if the ultimate goal of computational intelligence is to discover and emulate how the brain really learns, then the need for a general framework for learning from – and adapting to – a nonstationary environment can be hardly overstated. Given new data, such a framework would allow us to recognize when there has been a change, learn any novel content, reinforce existing knowledge that is still relevant, forget (or move to long term memory) what may no longer be relevant, only to be able to re-extract if and when such information becomes relevant again. Ensemble based systems can be used to address this problem by generating new classifiers as new data from the changing environment become available. The latest member of our Learn++ family of algorithms is Learn++.NSE (for Nonstationary Learning), which creates a new classifier for each batch of data that becomes available, and dynamically weighs them based on their time-adjusted performances on current and recent environments. The algorithm has been shown to track a variety of different concept drift scenarios very well. The algorithm and its results are discussed in detail in the following papers. For some movies and datasets see Learn++.NSE pages.
More recently, we have explored learning in nonstationary environments, when labeled data is available only initially, followed by unlabeled data only. This type of learning is also called learning under extreme verification latency, for which our COMPOSE algorithm have proven to be particularly effective.
- Umer M., Frederickson C., Polikar R., LEVELIW: Learning extreme verification latency with importance weighting, Int. Joint Conf. on Neural Networks (IJCNN 2017), pp. 1740– 1747, Anchorage AK, 2017. DOI: 10.1109/IJCNN.2017.7966061
- Frederickson C., Gracie T., Portley S., Moore M., Cahall D., Polikar R., “Adding adaptive intelligence to sensor systems with MASS,” 2017 IEEE Sensors Applications Symposium (SAS 2017), Glassboro, NJ, DOI: 10.1109/SAS.2017.7894084
- Umer M., Frederickson C., Polikar R., “Learning under extreme verification latency quickly: FAST COMPOSE,” 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, DOI: 10.1109/SSCI.2016.7849962.
- Sarnelle J., Sanchez A., Capo R., Haas J. and Polikar R., “Quantifying the Limited and Gradual Concept Drift Assumption,” Int. Joint Conf. on Neural Networks (IJCNN 2015), Ireland, 2015. DOI: 10.1109/IJCNN.2015.7280850
- G. Ditzler, M. Roveri, C. Alippi, and R. Polikar, “ Learning in Nonstationary Environments: A Survey,” IEEE Computational Intelligence Magazine, vol. 10, no. 4, pp. 12-25, 2015. DOI: 10.1109/MCI.2015.2471196. Best paper Award
- Ditzler G., Rosen G., Polikar R., “Domain Adaptation Bounds for Multiple Expert Systems Under Concept Drift,” Int. Joint Conf. on Neural Networks (IJCNN 2014), pp. 595-601, Beijing, China, July 2014 - Winner of IJCNN 2014 Best student paper award. DOI: 10.1109/IJCNN.2014.6889909
- Capo R., Sanchez A., Polikar R., “Core Support Extraction for Learning from Initially Labelled Nonstationary Environments using COMPOSE,” Int. Joint Conf. on Neural Networks (IJCNN 2014), pp. 602-608, Beijing, China, July 2014. DOI: 10.1109/IJCNN.2014.6889917
- Dyer K., Capo R., Polikar R., “COMPOSE: A Semi-Supervised Learning Framework for Initially Labeled Non-Stationary Streaming Data” IEEE Transactions on Neural Networks and Learning Systems, vol. 25, no. 1, pp. 12-26, 2014. DOI: 10.1109/TNNLS.2013.2277712
- Ditzler G. and Polikar R., “Incremental Learning of Concept Drift from Streaming Imbalanced Data,” IEEE Transactions on Knowledge and Data Engineering, vol. 25. No. 10, pp. 2283-2301, 2013. DOI: 10.1109/TKDE.2012.136
- Hoens, T.R., Polikar R., Chawla N., “Learning from streaming data with concept drift and imbalance: an overview,” Progress in Artificial Intelligence, vol. 1, no. 1, pp. 89-101, 2012.
- Elwell R. and Polikar R., “Incremental Learning of Concept Drift in Nonstationary Environments” IEEE Transactions on Neural Networks, vol. 22, no. 10, pp. 1517-1531, 2011. DOI:10.1109/TNN.2011.2160459
- Elwell R. and Polikar R., “Incremental Learning in Nonstationary Environments with Controlled Forgetting,” Int. Joint Conf. on Neural Networks (IJCNN 2009), pp. 771-778, Atlanta, GA June 2009.
- Elwell R. and Polikar R., ”Incremental Learning of Variable Rate Concept Drift,” Multiple Classifier Systems (MCS 2009), Lecture Notes in Computer Science, J.A. Benediktsson et al, eds., vol. 5519, pp. 142-151, Reykjavik, Iceland, June 2009.
- Karnick M., Muhlbaier M., Polikar R., “Incremental Learning in Non-stationary Environments with Concept Drift using a Multiple Classifier Based Approach,” International Conference on Pattern Recognition (ICPR2008), Tampa, FL, December 2008.
- Karnick M., Ahiskali M., Muhlbaier M., Polikar R., “Learning Concept Drift in Nonstationary Environments Using an Ensemble of Classifiers Based Approach,” IEEE World Congress on Computational Intelligence, pp. 3455-3462, Hong Kong, June 2008.
- Muhlbaier M., Polikar R., “Multiple classifiers based incremental learning algorithm for learning nonstationary environments,” IEEE International Conference on Machine Learning and Cybernetics (ICMLC 2007), pp. 3618-3623, Hong Kong, China, August 2007.
- Muhlbaier, M.D., and Polikar, R., “An ensemble approach for incremental learning in nonstationary environments,” 7th Int. Workshop on Multiple Classifier Systems, in Lecture Notes in Computer Science, vol. 4472, pp. 490-500, Berlin: Springer, 2007.
Learning Concept Drift from Imbalanced Data
As mentioned above, Learn++.NSE provides an attractive solution to a number of concept drift problems under different drift rates and drift scenarios. However, the core of this algorithm relies on error to weigh the classifiers in the ensemble on the most recent data. For balanced class distributions, this approach works very well, but when faced with imbalanced data, where there are far too many samples in one class, compared to another class, simple classification error is no longer an acceptable measure of classifier performance on either of the majority or minority classes. While there is some literature available for learning in nonstationary environments (such as Learn++.NSE) and imbalanced data (such as SMOTE) separately, the combined problem of learning in nonstationary environment from unbalanced data is underexplored. Therefore, we developed modified versions of the Learn++.NSE framework that can be used to incrementally learn from imbalanced data in a nonstationary environment. One such approach is simply to combine Learn++.NSE with SMOTE (which we call Learn++.CDS), but an alternate approach is to use a different error function that independently optimizes performance on minority and majority data, while using subensembles to repeatedly sample entire minority data along with subsets of the majority data. We call the latter Learn++.NIE (for learning in Nonstationary and Imbalanced Environments). The preliminary results of these works can be found in the following publications.
- Ditzler G., Polikar R., “Semi-supervised Learning in Nonstationary Environments,” Int. Joint Conf. on Neural Networks (IJCNN 2011), San Jose, CA, - to appear , August 2011.
- Ditzler G., Polikar R., “Hellinger Distance Based Drift Detection for Nonstationary Environments,” IEEE Symposium Series on Computational Intelligence (SSCI 2011), pp. 41-48, doi: 10.1109/CIDUE.2011.5948491 Paris, France, 2011.
- Ditzler G., Chawla N., Polikar R. “An Incremental Learning Algorithm for Nonstationary Environments and Class Imbalance,” Int. Conference on Pattern Recognition (ICPR 2010), pp. 2997-3000 , doi: 10.1109/ICPR.2010.734 Istanbul, Turkey, August 2010.
- Ditzler G. and Polikar R., “An Incremental Learning Framework for Concept Drift and Class Imbalance,” IEEE/INNS Int. Joint Conf. on Neural Networks / World Congress on Computational Intelligence (IJCNN / WCCI 2010), pp. 1-8 , doi: 10.1109/IJCNN.2010.5596764 Barcelona, Spain, July 2010.
- Ditzler G., and Polikar R., “Incremental Learning of New Classes in Unbalanced Datasets: Learn++.UDNC,” Multiple Classifier Systems (MCS 2010), Lecture Notes in Computer Science, N. El Gayar et al., eds., vol. 5997, pp. 33-42, Cairo, Egypt, April 2010.
Incremental Learning
One of the biggest frustrations that many researchers working on classifiers face is that most classifiers cannot be “further trained” with new data without forgetting what has been learned earlier. This is particularly true for many of the most common neural network schemes, such as multilayer perceptron, radial basis function network, etc. Learning additional information provided by new data requires discarding the old network, combining old and new data and re-training from scratch. This solution not only forgets what has been learned earlier (also known as catastrophic forgetting), but it is useless if the original data is no longer available. The purpose of our NSF funded work is to develop an algorithm that will allow any classification algorithm learn incrementally from new data in the absence of old data. The idea is in part inspired by Shapire’s boosting algorithm which was originally developed for improving the accuracy of weak learning algorithms. The new algorithm, called Learn++, uses an ensemble of classifiers instead of a single classifier to learn incrementally, and it has shown to be effective in incremental learning, even when additional data introduce new classes. Scroll down to see a figure for algorithm pseudocode and block diagram.
The following papers describe the Learn++ algorithm, and its recent variations. Also see the Learn++.NC movie, and additional details at Learn++.NC page
- Muhlbaier M., Topalis A., Polikar R., “Learn++.NC: Combining Ensemble of Classifiers Combined with Dynamically Weighted Consult-and-Vote for Efficient Incremental Learning of New Classes,” IEEE Transactions on Neural Networks, vol. 20, no. 1, pp. 152 – 168, 2009.
- Cevikalp H. and Polikar R., “Local classifier weighting by quadratic programming,” IEEE Transactions on Neural Networks, vol. 19, no. 10, pp. 1832 – 1838, 2008.
- Syed-Mohammed H., Leander J., Marbach M., and Polikar R., “Can AdaBoost.M1 learn incrementally? A comparison to Learn++ under different combination rules,” Int. Conf. on Artificial Neural Networks (ICANN2006), Lecture Notes in Computer Science (LNCS) , vol. 4131, pp. 254-263, Athens, Greece. Berlin: Springer, 2006.
- Erdem Z., Polikar R., Gurgen F., Yumusak N., “Ensemble of SVM Classifiers for Incremental Learning,” 6th Int. Workshop on Multiple Classifier Systems (MCS 2005), Springer Lecture Notes in Computer Science (LNCS), vol. 3541, pp. 246-255, Seaside, CA, June 2005.
- Gangardiwala A. and Polikar R. , “Dynamically weighted majority voting for incremental learning and comparison of three boosting based approaches,” Proc. of Int. Joint Conf. on Neural Networks (IJCNN 2005), pp. 1131-1136, Montreal, QB, Canada, July 2005.
- Muhlbaier M., Topalis A., Polikar R., “Incremental learning from unbalanced data,” Proc. of Int. Joint Conference on Neural Networks (IJCNN 2004), vol. *, pp. 1057-1062, Budapest, Hungary, July 2004.
- Muhlbaier M., Topalis A., Polikar R., “Learn++.MT: A new approach to incremental learning,” 5th Int. Workshop on Multiple Classifier Systems (MCS 2004), Springer LINS vol. 3077 , pp. 52-61, Cagliari, Italy, June 2004.
- Polikar R., Udpa L., Udpa S., Honavar V., “An incremental learning algorithm with confidence estimation for automated identification of NDE signals,” IEEE Transactions on Ultrasonics, Ferroelectrics and Frequency Control, vol. 51, no. 8, pp. 990-1001, 2004.
- Polikar R., Udpa L., Udpa, S., Honavar, V., “Learn++: An incremental learning algorithm for supervised neural networks,” IEEE Transactions on System, Man and Cybernetics (C), Special Issue on Knowledge Management, vol. 31, no. 4, pp. 497-508, 2001 (ORIGINAL PAPER)
- Polikar R., Byorick J., Krause S., Marino A., Moreton M., “Learn++: A classifier independent incremental learning algorithm for supervised neural networks,” Proc. of Int. Joint Conference on Neural Networks (IJCNN 2002), vol. 2, pp. 1742-1747, Honolulu, HI, 12-17 May 2002.
- Polikar R., Krause S., Burd L., “Dynamic weight update in weighted majority voting for Learn++,” Proc. of Int. Joint Conference on Neural Networks (IJCNN 2003), vol. 4, pp. 2770-2775, Portland, OR, 20-24 July 2003.
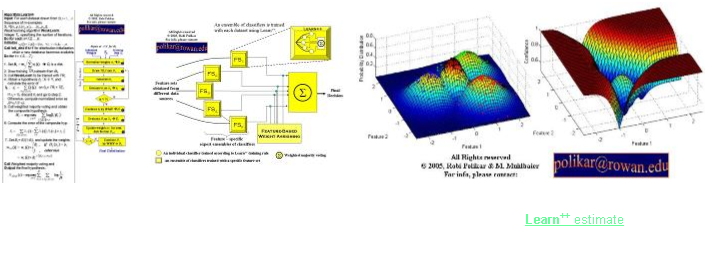
The pseudocode of the original Learn++ algorithm, its block diagram, and its .m file are also available to the community.
Data Fusion
In many applications that call for automated decision making, it is not unusual to receive data obtained from different sources that may provide complementary information. A suitable combination of such information is usually referred to as data or information fusion, and can lead to improved accuracy and confidence of the classification decision compared to a decision based on any of the individual data sources alone. Consequently, both incremental learning and data fusion involve learning from different sets of data. If the consecutive datasets that later become available are obtained from different sources and/or consist of different features, the incremental learning problem turns into a data fusion problem. Therefore a suitable modification of Learn++ can be used for data fusion, where a new ensemble of classifiers are generated for each source that generates a different database. The following is a list of data fusion related papers on Learn++.
- Parikh D. and Polikar R., “An Ensemble based incremental learning approach to data fusion, IEEE Transactions on Systems, Man and Cybernetics, vol. 37, no.2, pp. 437-500, 2007
- Polikar R., Topalis A., Green D., Kounios J., Clark C.M., Comparative multiresolution analysis and ensemble of classifiers approach for early diagnosis of Alzheimer’s disease, Computers in Biology and Medicine, vol. 37, no. 4, pp. 542-558, 2007.
- Polikar R., Topalis A., Green D., Kounios J., Clark C.M., Ensemble based data fusion for early diagnosis of Alzheimer’s disease, Information Fusion, vol. 9, no. 1, pp. 83-95, 2008.
- Lewitt M. and Polikar R., “An ensemble approach for data fusion with Learn++,” 4th Int. Workshop on Multiple Classifier Systems (MCS 2003), Springer LINS vol. 2709 , pp. 176-185Surrey, England, June 11-13 2003.
- Parikh D. and Polikar R. , “A Multiple Classifier Approach for Multisensor Data Fusion,” Proc. of IEEE FUSION 2005, vol. 1, pp: 453-460, Philadelphia, PA July 2005.
- Parikh D., Kim M., Oagaro J., Mandayam S. and Polikar R., “Combining classifiers for multisensor data fusion,” Proc. of Int. IEEE Conf. on System Man Cybernetics (SMC 04), pp. 1232-1237, The Hague, The Netherlands, October 2004.
- Parikh D., Kim M., Oagaro J., Mandayam S. and Polikar R., “Ensemble of classifiers approach for NDE data fusion,” Proc. of 2004 IEEE Int. Ultrasonics, Ferroelectrics and Frequency Control Joint Conf (UFFC2004), vol. 2, pp. 1062-1065, Montreal, Canada, August 2004.
Confidence Estimation
Ensemble based systems can also be used to estimate the confidence of a classifier’s decision on any given instance. Intuitively, given a group of classifiers that classify a given instance, if all –or most—classifiers agree on the decision, we can reasonably assume that the classification system has high confidence in its decision. On the other hand, if the decision is made by just a slight majority, then there is less confidence in the decision. This idea can be formalized to estimate the confidence of a decision. In fact, we can use this approach to estimate the posterior probability of a class given a measurement vector. The following papers describe how Learn++ can be used for confidence estimation.
- Muhlbaier M., Topalis A., Polikar R., “Ensemble confidence estimates posterior probability,” 6th Int. Workshop on Multiple Classifier Systems (MCS 2005), Springer Lecture Notes in Computer Science (LNCS), vol. 3541, pp. 326-335, Seaside, CA, June 2005.
- Byorick J. and Polikar R., “Confidence estimation using incremental learning algorithm, Learn++,” Int. Conf. on Artificial Neural Networks (ICANN 2003), Springer LINS vol. 2714, pp. 181 – 188, Istanbul, Turkey, 26-29 June 2003.
Missing Feature
Many classification algorithms, including most popular neural network architectures, require that the number and nature of the features be set before the training. Since the underlying operation for most classifiers is a matrix multiplication, instances missing even a single feature cannot be processed by such classifiers, due to the missing number(s) in the vectors/matrices to be multiplied. Hence, the field or test data to be evaluated by the classifier must contain exactly the same set and number of features as the training data used to create the neural network to make a valid classification. Missing data in real world applications is not an uncommon occurrence, however. It is not unusual for training, validation or field data to have missing features in some (or even all) of their instances, as bad sensors, failed pixels, malfunctioning equipment, unexpected noise causing signal saturation, data corruption, etc. are all familiar scenarios in many practical applications. The missing feature problem can also be addressed by an ensemble based approach. Under the assumption that the feature set is redundant, we can train a sufficiently large number of classifiers, each with a random subset of the features, and instances with missing features are then classified by the majority voting of those classifiers whose training data did not include the missing features. We call the resulting algorithm Learn++.MF (for missing feature). The following papers describe the Learn++.MF algorithm.
- Polikar R., DePasquale J., Syed Mohammed H., Brown G., Kuncheva L.I., “Learn++.MF: A Random Subspace Approach for the Missing Feature Problem,” Pattern Recognition, vol. 43, no. 11, pp. 3817-3832, 2010 .
- DePasquale, J. and Polikar R., “Random feature subset selection for ensemble based classification of data with missing features,” 7th Int. Workshop on Multiple Classifier Systems, in Lecture Notes in Computer Science, vol. 4472, pp. 251-260, Springer, 2007.
- H. Syed-Mohammed, N. Stepenosky and R. Polikar, “An Ensemble Technique to Handle Missing Data from Sensors,” IEEE Sensor Applications Symposium, Houston, TX, February 2006.
- Krause S. and Polikar R., "An ensemble of classifiers for the missing feature problem,” Proc. of Int. Joint Conference on Neural Networks (IJCNN 2003), vol. 1, pp. 553-558, Portland, OR, 20-24 July 2003.
For a complete list of our works please see List of Publications
Acknowledgement
Machine Learning research at Signal Processing and Pattern Recognition Laboratory is primarily funded byNational Science Foundation Electrical and Communications Systems Division
Power, Controls and Adaptive Systems program and through the CAREER program,
under grants ECS 0239090, ECCS 0926159, and ECCS 1310496,
The material provided here is based upon work supported by the National Science Foundation under Grant No ECS-0239090, “CAREER: An Ensemble of Classifiers Based Approach for Incremental Learning,” by Grant No ECCS 0926159 Incremental Learning from Unbalanced Data in Nonstationary Environments , and by Grant No. ECCS 1310496 Learning from Initially Labeled Nonstationary Streaming Data. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Contact
For more information on what SPPRL can do for your company / institution, please contact Dr. Robi Polikar at
346 Rowan Hall, Dept. of Electrical and Computer Engineering Rowan University,
201 Mullica Hill Road, Glassboro, NJ 08028
Phone: (856)256-5372 Fax: (856)256-5241
E-Mail: polikar@rowan.edu